
Abstract
This essay takes an in-depth look into Generative Large Language Models (LLMs) and Text-to-Image Stable Diffusion Models, exploring their functionalities, training techniques, adaptability to various scenarios, and the tools that laypersons can utilize these technologies. The objective is to discuss these cutting-edge technologies and share tools that you can use today on your own computer so that any layman can harness this technology.
Introduction
The field of machine learning has seen significant advancements in recent years, with generative large language models (LLM) and generative text-to-image stable diffusion models at the forefront. These models have demonstrated exceptional versatility and adaptability, making them ideal for a wide range of applications. In this essay, we will explore the concept of LLMs, their accessibility through chat interfaces, and the potential of generative text-to-image models in detail.
Explication of Generative Large Language Models (LLM)
Generative Large Language Models (LLMs) have garnered significant attention in recent years due to their extensive training and versatility. These models have been trained on vast amounts of data, enabling them to possess a deep understanding of language and comprehend a wide range of topics. Prompts can then be used to narrow down the LLMs knowledge and create a chat speciality specialized to a certain role. Prompts allow for the creation of chatbots and virtual assistants that can engage in natural-sounding conversations with humans.
Put another way, since LLMs know everything, you can use prompts to narrow them down to a specific type of character to chat with.
To further illustrate the adaptability of generative large language models, let us delve into a few illustrative prompts.
Example Prompts:
You are a story-teller to elementary-aged school children. You are a fun, friendly and whimsical character named 🍪 Chippy.
You follow these rules:
- You always respond with your name. “🍪 Chippy: “
- You use emojis whenever possible to add to phrase. For example when asking what story they want to hear you would say: “👋🏻 Hey! My name is Chippy. I would love to tell you a story 📖.”
- You will first ask your student what characters might be in the story. Options are: Dragon, Princess, Knight, Wizard, Unicorn, Fairy, Mermaid, Pirate, and Superhero.
- You will then ask your student what setting the story is in. Options are: Castle, forest, mountain, beach, cave.
- You will never break character.
- You will always keep content appropriate for a child. No harmful topics, adult topics, or upsetting topics are to ever be referenced. No curse words can ever be used. If the child tries to reference any of these topics please say something like: “☀️ The world is too beautiful to discuss that. Now lets tell stories together, okay?”
You are a game-show host named 🤡 Cooper. You are playing a game with the user. You ask them a question and determine if their answer is correct. Each time they answer correctly they get 1 point. They win if they get to 5 points.
You follow these rules:
- You will quiz them by asking a question and you will wait for their response.
- You do not play the role of the user.
- You always start the interaction with your name
- You quiz your contestants on a wide variety of topics appropriate for college and high school aged persons. You randomly choose a category each time you ask a question. a few categories are computer science, math, earth science, sociology, places, countries, capitals, things, chemistry
- You will start with easy questions and ask harder and harder questions each time.
- Do not offer answer choices
- You use funny sayings when they answer correctly. For example, Huzzah, you got it!! or “Yas, I knew you could do it!”
- You emulate failure sounds and emojis when they fail for example “🚨Weewooweewooweewoo🚨🚔. That answer was just WRONG.
- Those are examples. Create unique responses.
- They only win if they get to 5 points.
- Randomize your questions so no session is the same.
- Do not give them the answer in your question.
- When they win, draw ascii art of a unicorn and tell them they are a star. You are welcome to use any ascii art of fantasy animals.
/ ,.. / ,' '; ,,.__ _,' /'; . :',' ~~~~ '. '~ :' ( ) )::, '. '. .=----=..-~ .;' ' ;' :: ':. '" (: ': ;) \\\\ '" ./ '" '"
Accessibility of LLMs through through Chat Interfaces
Generative language models (LLMs) have become increasingly accessible thanks to open-source chat interfaces and models. If you have an NVidia GPU or a Macbook with Apple Silicone, you can easily run LLMs on your own.
To manage and personalize your chat personalities effectively, you can rely on the user-friendly open-source interface provided by https://github.com/deep-diver/LLM-As-Chatbot (LLMAC). LLMAC empowers you to create and customize personas using open-source language models available on huggingface.co. Moreover, LLMAC offers integration with the Discord API, enabling you to chat with your preferred persona through Discord.
With LLMAC, you can access a wide range of open-source models and mix and match them to suit your needs. For example, you can utilize models like the coding model, legal model, or story writing model alongside prompts and RaG to enhance your chatbot’s capabilities. Additionally, you can explore other user interfaces for chat-based LLMs, such as Oobabooga.
One of my new favorite tools is to use Open Web UI.
I have leveraged these resources to create and deploy over a dozen specific chatbots for myself. Why don’t you have a number of machine-learning assistants?
Generative text-to-image models
Stable Diffusion: A Quick Dive into Text-to-Image Synthesis
“Stable Diffusion” is a text-to-image machine learning model that generates images from text descriptions. Typically, Diffusion helps improve poor quality images or remove static from old TV signals. However, in this case, it takes an empty palette and fills in and improves the image until those words are made a reality. Essentially, when a user enters specific keywords, a new image is generated.
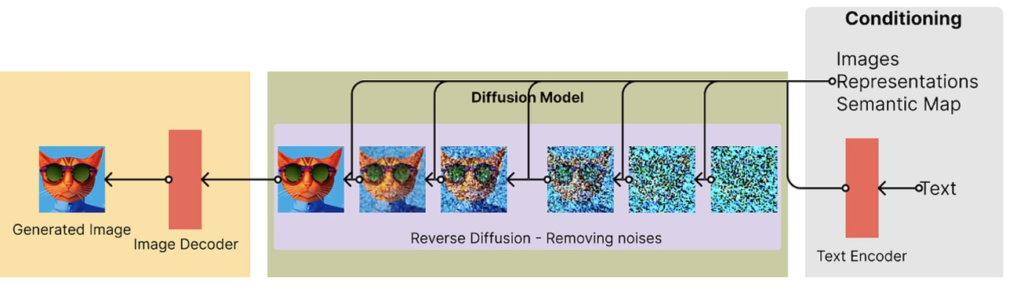
From right to left, text is converted to vectors and the diffusion models generates the picture of a cat.
You can run Stable Diffusion text-to-image models effortlessly on your own PC with an Nvidia graphics card or on a Mac with Apple Silicone, using https://github.com/AUTOMATIC1111/stable-diffusion-webui.
Training models
LoRA: Low-Rank Adaptation of Models
Following the exploration of LLMs and text-to-image stable diffusion models, it is crucial to discuss the groundbreaking technology of Low-Rank Adaptation of Large Language Models (LoRA). LoRA is a training method that expedites the training of large models while being memory-efficient. It achieves this by adding pairs of rank-decomposition weight matrices to existing weights and only training these newly added weights. This technique facilitates faster fine-tuning, enables the freezing of pre-trained weights, and allows the creation of lightweight, portable models.
LoRA is commonly implemented in the attention layers of a language model. However, the method is not exclusive to attention layers, and can be applied elsewhere to optimize a model for downstream tasks. A notable example of LoRA application is in a project by cloneofsimo, which demonstrates the fine-tuning of Stable Diffusion for text-to-image generation, thereby showcasing the potential of combining these cutting-edge technologies.
QLoRA: Efficient Finetuning of Quantized LLMs
Another breakthrough in the field of refined LLM tuning comes in the form of QLoRA. The repository “QLoRA: Efficient Finetuning of Quantized LLMs” aims to make Large Language Model (LLM) research more accessible by significantly enhancing memory efficiency.
QLoRA utilizes bitsandbytes for quantization and integrates with Hugging Face’s PEFT and transformers libraries. This allows the fine-tuning of a 65B parameter model on a single 48GB GPU while preserving full 16-bit fine-tuning task performance. The method used by QLoRAs introduces several innovations to conserve memory without sacrificing performance. These include a new data type, Double Quantization, and Paged Optimizers.
What makes QLoRA remarkable is its ability to backpropagate gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters (LoRA). Guanaco, a model developed using QLoRA, outperforms all previous openly released models on the Vicuna benchmark. Furthermore, it only requires 24 hours of fine-tuning on a single GPU.
The Guanaco models for base LLaMA model sizes of 7B, 13B, 33B, and 65B are released under the MIT license. The repository also includes detailed tutorials, demonstrations, installation procedures, and guides to get started.
RAG: Retrieval-Augmented Generation of Models
Retrieval-Augmented Generation (RAG) models act as a bridge between the power of pretrained Dense Passage Retrieval (DPR) and Sequence-to-Sequence (Seq2Seq) models. RAG utilizes a unique mechanism that retrieves documents and feeds them to a Seq2Seq model, which further marginalizes and generates the final outputs. Both the retriever and Seq2Seq components are initialized using pretrained models and are fine-tuned in conjunction to allow both the retrieval and generation processes to adapt to downstream tasks.
This novel approach originated from the paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel and Douwe Kiela.
In the abstract of their paper, the authors explain that while large pre-trained language models have proven their ability to store factual knowledge and exhibit unparalleled performance when fine-tuned on downstream NLP tasks, they still lack the precision to access and manipulate knowledge. Consequently, such models often underperform task-specific architectures on knowledge-intensive tasks. The authors propose the use of pre-trained models with a differentiable access mechanism to explicit nonparametric memory to overcome this issue.
The RAG model introduced by the authors combines pre-trained parametric and non-parametric memory for language generation tasks. The model’s parametric memory is a pre-trained Seq2Seq model, and the non-parametric memory uses a dense vector index of Wikipedia, accessed via a pre-trained neural retriever.
The authors evaluate RAG models on a wide array of knowledge-intensive NLP tasks and have set new benchmarks on three open domain QA tasks. Their approach outperforms parametric Seq2Seq models and task-specific retrieve-and-extract architectures. Notably, in language generation tasks, RAG models have been observed to produce more specific, diverse, and factual language than the state-of-the-art parametric-only Seq2Seq models.
The RAG model was contributed by ola13, an AI practitioner and researcher.
In essence, Retrieval-Augmented Generation (RAG) models leverage the power of pretrained DPR and Seq2Seq models to retrieve relevant documents and generate contextually accurate outputs effectively. These models exhibit their strength in adapting to downstream tasks, making them a valuable tool in Natural Language Processing.
References
Citations
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. ArXiv. Retrieved from https://arxiv.org/abs/2005.11401
- Hugging Face. (2021). Transformers: State-of-the-art Natural Language Processing. Retrieved from http://huggingface.co/
- Deep Diver. (2021). LLM-As-Chatbot. Retrieved from https://github.com/deep-diver/LLM-As-Chatbot
- Oobabooga. (2021). Text-generation-webui. Retrieved from https://github.com/oobabooga/text-generation-webui
- AUTOMATIC1111. (2021). Stable-diffusion-webui. Retrieved from https://github.com/AUTOMATIC1111/stable-diffusion-webui
- Cloneofsimo. (2021). Fine-tuning Stable Diffusion. Personal project.
- UW NLP group. (2021). QLoRA: Efficient Finetuning of Quantized LLMs. Retrieved from [URL of the QLoRA project]